
Key Insights and Findings: (a) Naively mixing diverse 3D datasets hurts dense baselines. (b) Sparse MoE routing improves both seen and zero-shot performance without dataset IDs. (c) Experts organically specialize from heterogeneous geometry and semantics.

While massively scaling both data and models has become central in NLP and 2D vision, their benefits for 3D point cloud understanding remain limited. We study the initial step of scaling 3D point cloud understanding under a realistic regime: large-scale multi-dataset joint training for 3D semantic segmentation, with no dataset labels at training or inference time. Point clouds arise from diverse sensors (e.g., depth cameras, LiDAR) and scenes (e.g., indoor, outdoor), yielding heterogeneous scanning patterns, sampling densities, and semantic biases; naively mixing such datasets degrades standard models. We introduce Point-MoE, a Mixture-of-Experts design that expands model capacity through sparsely activated expert MLPs and a lightweight top-k router, enabling token-level specialization without dataset supervision. Trained on diverse indoor and outdoor datasets and evaluated on seen as well as zero-shot settings, Point-MoE outperforms prior methods while requiring no dataset labels for either training or inference. This outlines a scalable path for 3D perception: letting the model discover structure in heterogeneous 3D data rather than imposing it via manual curation or dataset-specific heuristics.
Given a 3D scene represented as a point cloud \( \mathcal{P} = \{p_i\}_{i=1}^{n} \), semantic segmentation predicts a class label \( \hat{y}_i \in \mathcal{C} \) for each point. Let each dataset be \( \mathcal{D}_j = \{(\mathcal{P}_t, \mathbf{y}_t)\} \), and the multi-dataset training collection be \( \mathbb{D} = \{\mathcal{D}_j\} \). The goal is to learn one unified model over \( \mathbb{D} \) that performs well on seen datasets and generalizes to zero-shot datasets from unseen distributions.
We do not assume oracle dataset labels during training or inference. To bridge label discrepancies across datasets, we follow prior work and align point features with CLIP text embeddings of class names, enabling language-guided supervision under a unified training protocol.
Mixture-of-Experts (MoE) Layer. Point-MoE routes input tokens to a sparse subset of expert networks using a lightweight gating function. For each input feature vector, a top-k subset of experts is selected and combined via weighted averaging. This expands model capacity while preserving efficiency, and encourages emergent expert specialization under heterogeneous multi-dataset training.
Integration into PTv3. We build on Point Transformer V3 (PTv3) and apply MoE at the attention output projection \(W_o\) in each block, while keeping \(W_q, W_k, W_v\) dense. This placement provides stronger gains than FFN-only MoE under comparable expansion and keeps the backbone structure stable.
Language-Guided Classification. To bridge label gaps across datasets, we align point features with CLIP text embeddings of class names. This enables supervision across mismatched taxonomies (e.g., "pillow" exists in Structured3D but not ScanNet) without requiring dataset labels.
Mixed-Dataset Training. Each minibatch jointly samples from indoor and outdoor datasets. This improves optimization stability and promotes cross-dataset expert specialization by exposing experts to diverse tokens within each update step.
Efficiency and Generalization. Because only a sparse subset of experts is activated per token, Point-MoE improves the accuracy-compute trade-off while maintaining strong seen-dataset performance and robust zero-shot generalization.
Training efficiency and validation mIoU. THe below figure shows the training loss and validation mIoU curves for four models: the baseline PTv3-L, its improved variant PTv3-Mix-LN (which incorporates mixed-domain batches and LayerNorm), PPT-L, and our proposed Point-MoE-L. All models are trained from scratch across multiple domains. Point-MoE-L converges faster and achieves strong validation mIoU without using explicit dataset labels, matching or exceeding the performance of PPT-L trained with ground-truth domain labels. While all models reach similar training loss, only Point-MoE-L and PPT-L generalize effectively—reinforcing that low training loss is not indicative of strong cross-domain performance. On ScanNet, Structured3D, Matterport3D, and nuScenes, Point-MoE-L shows consistent improvement and avoids early plateaus seen in PPT-L, especially on Structured3D, suggesting stronger long-term learning. PTv3-L fails to generalize and exhibits unstable validation curves.

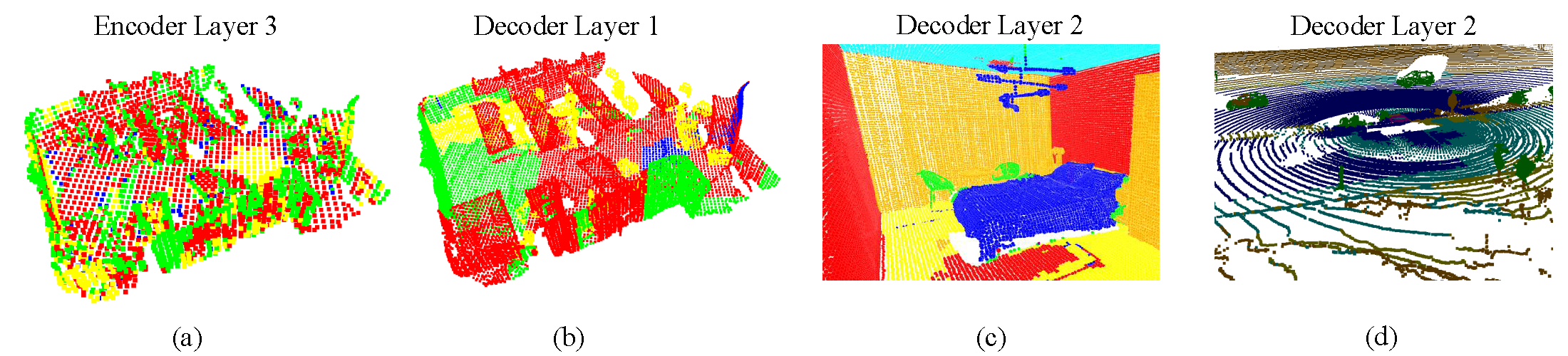
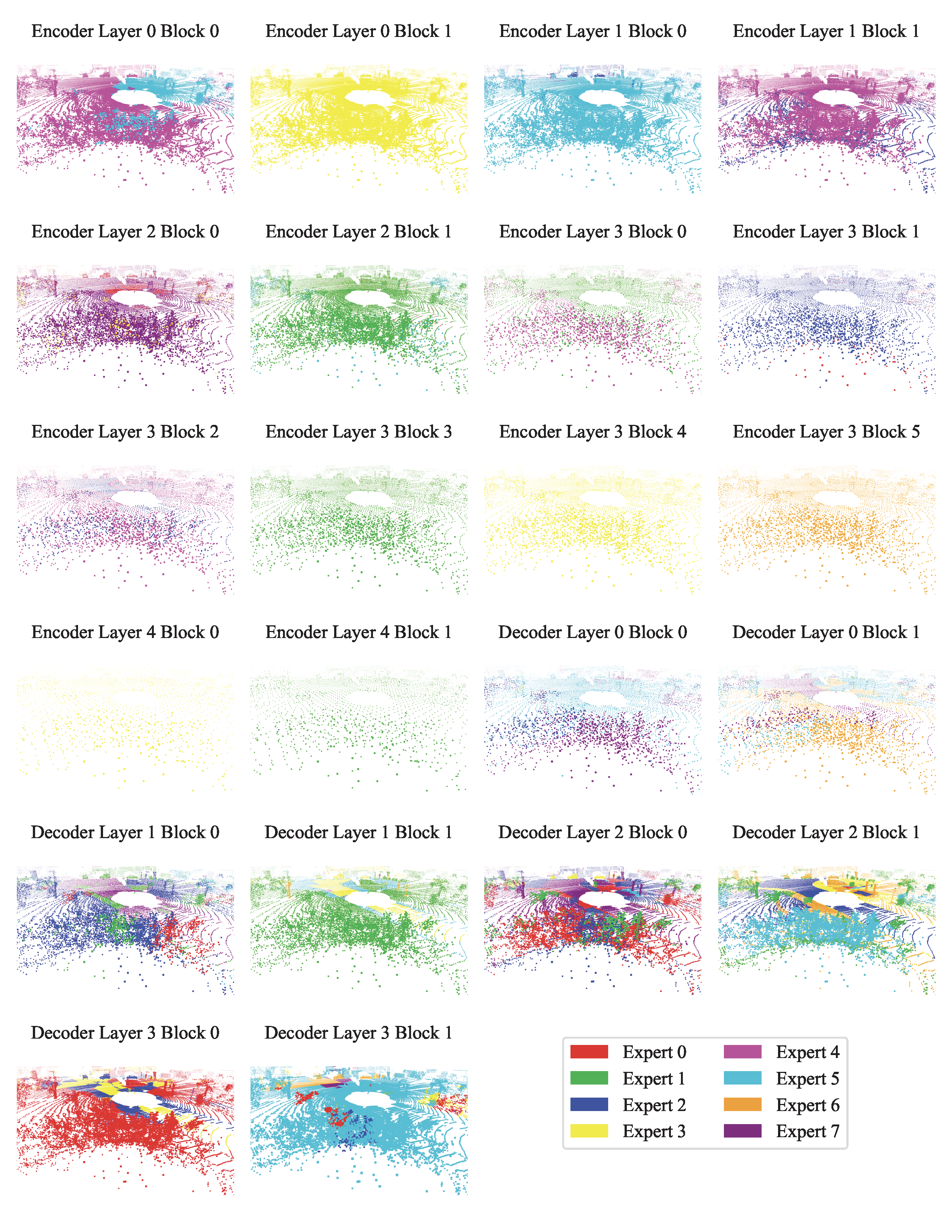
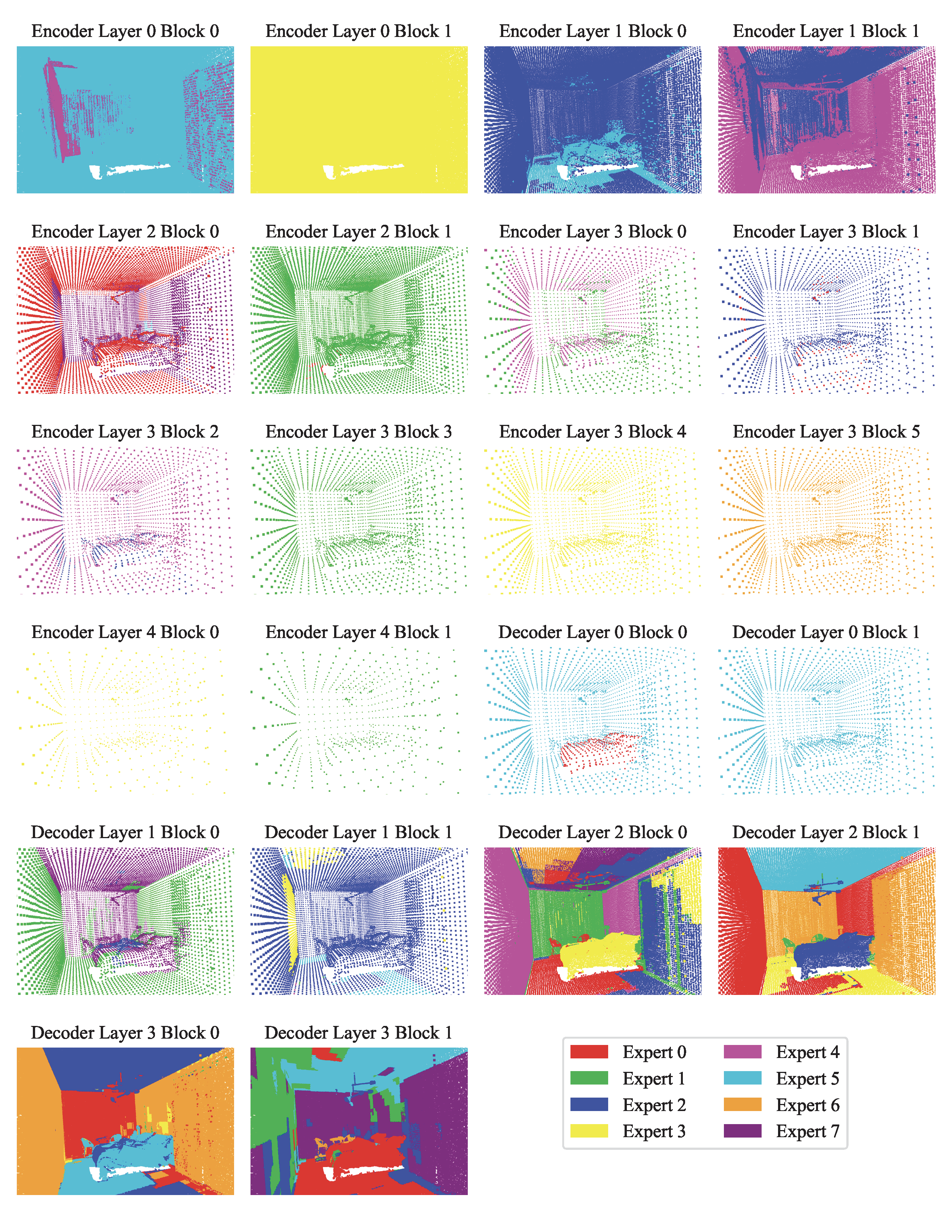
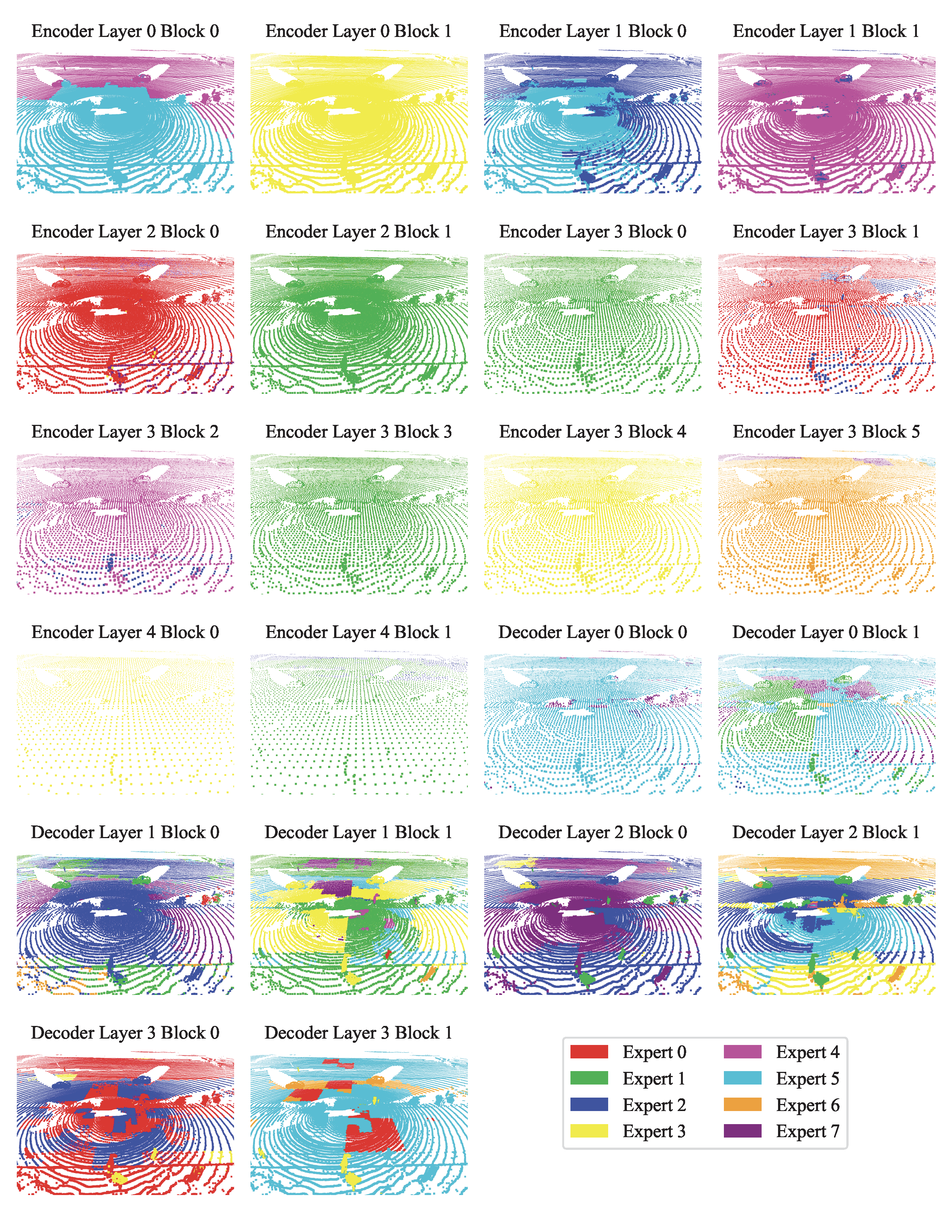
Expert choice visualization. The below figure showcases expert assignments for a validation scene at selected layers. In (a), we observe that early encoder layers rely heavily on geometric cues for routing. For instance, green experts are consistently activated along object boundaries such as the edges of desks and chairs, while red experts dominate flat surfaces. In (b) and (c), the decoder layers exhibit more semantically meaningful expert selection—likely due to their proximity to the loss function—with distinct experts attending to objects like desks, chairs, floors, and walls. In (d), we examine an outdoor scene with sparse LiDAR data. Despite limited geometric structure, the model still organizes routing meaningfully: nearby points are routed to blue experts, while farther points activate red experts. We include more visualizations in the appendix for completeness. We also note occasional visual artifacts where isolated points are assigned different experts than their neighbors, which may be related to PTv3's architectural choices such as point serialization or positional encoding.
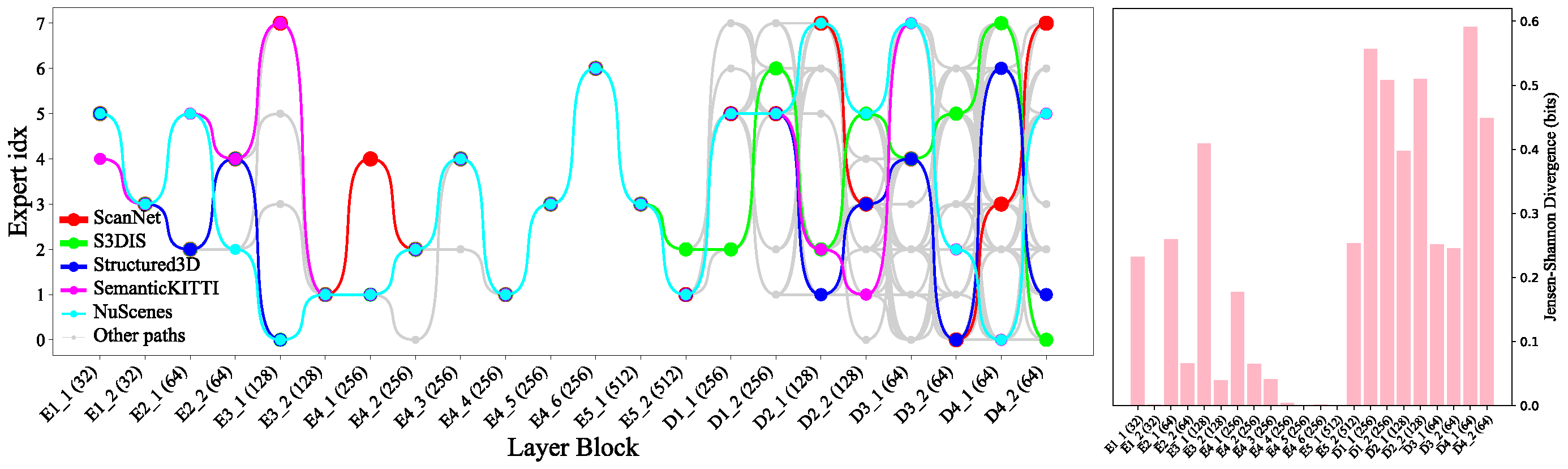
Token pathways. To understand how Point-MoE adapts to diverse domains, we analyze expert routing behavior at the token level. Specifically, we track the top-1 expert assignment for each token across all MoE layers and construct full routing trajectories from the final layer back to the first. We then identify the top 100 most frequent expert paths based on their occurrence across all tokens. As shown in the next figure, encoder expert paths are substantially less diverse than those in the decoder, indicating that encoder layers perform more domain-agnostic processing. Interestingly, we observe a sparse routing pattern in deeper encoder layers. This may be attributed not to feature reuse, but to the U-Net-style design where features are spatially deep but token sparsity increases, resulting in reduced variability in routing decisions.
When examining domain-level trends, we find that certain dataset pairs—such as SemanticKITTI and nuScenes or ScanNet and Structured3D—share similar expert pathways, suggesting that Point-MoE implicitly clusters domains with related geometric or semantic structures. To quantify these observations, we compute the Jensen-Shannon Divergence JSD between expert selection distributions across datasets at each MoE layer. JSD is an entropy-based measure of divergence between expert routing distributions across datasets, weighted by their token proportions; its formal definition is provided in the supplementary. As shown in the next figure (right), decoder layers exhibit significantly higher JSD, indicating stronger domain-specific specialization. Several encoder layers also display nontrivial JSD, underscoring the benefit of placing MoE throughout the network.
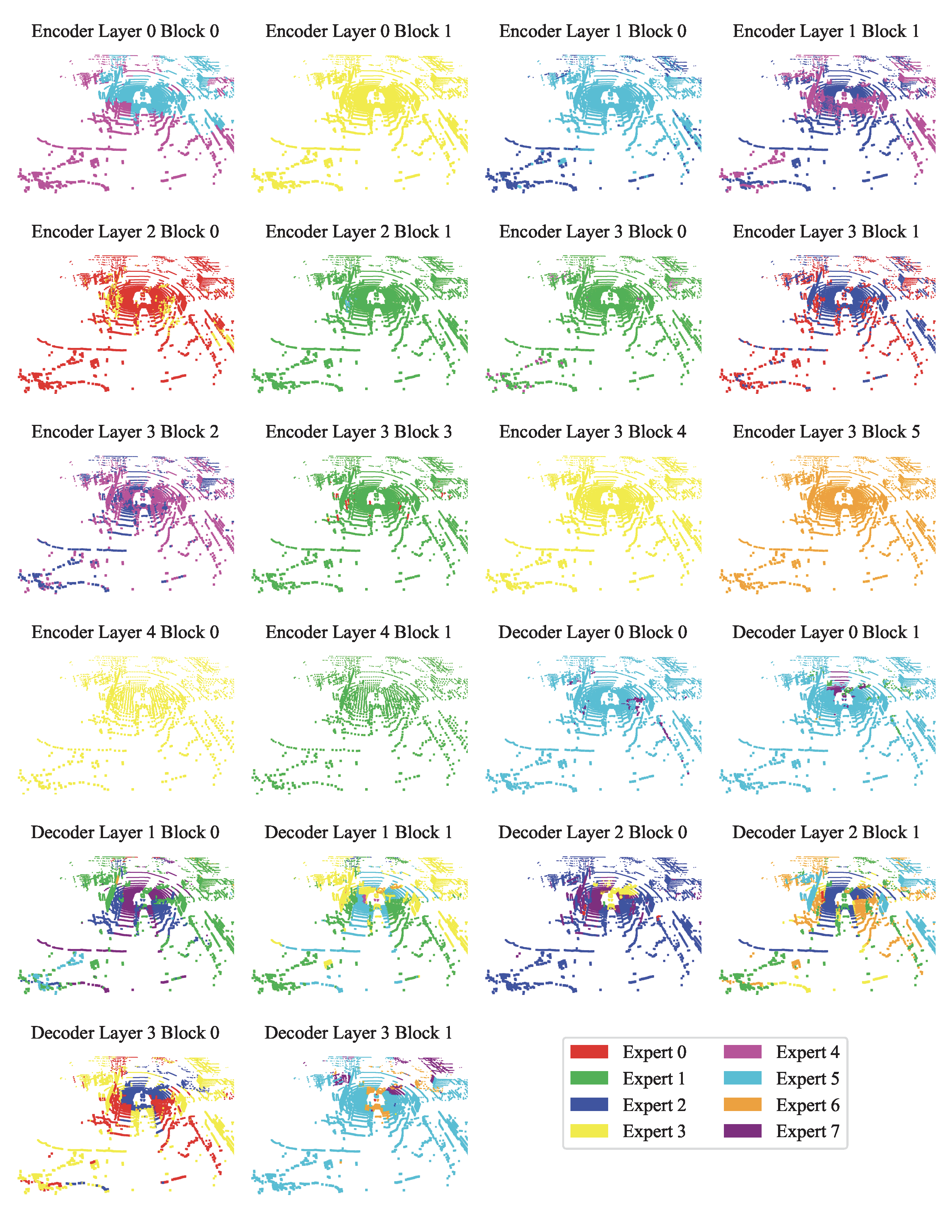
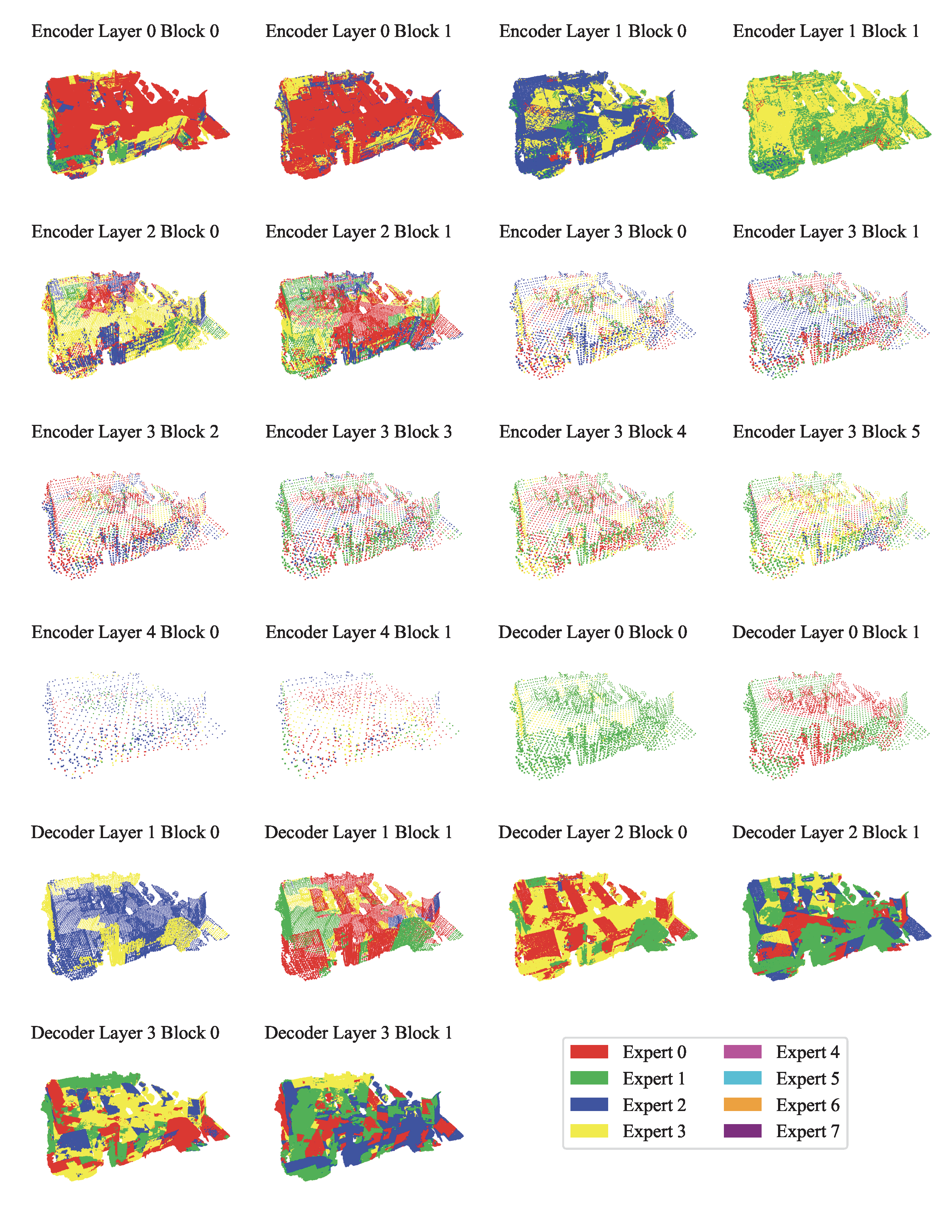
| Visualization Type | Description | Link |
|---|---|---|
| Expert Choice Visualization on Matterport3D | Visualization on each layer of the encoder and decoder. | View |
| Expert Choice Visualization on nuScenes | Visualization on each layer of the encoder and decoder. | View |
| Expert Choice Visualization on S3DIS | Visualization on each layer of the encoder and decoder. | View |
| Expert Choice Visualization on ScanNet | Visualization on each layer of the encoder and decoder. | View |
| Expert Choice Visualization on SemanticKITTI | Visualization on each layer of the encoder and decoder. | View |
| Expert Choice Visualization on Structured3D | Visualization on each layer of the encoder and decoder. | View |
| Expert Choice Visualization on Waymo | Visualization on each layer of the encoder and decoder. | View |
@inproceedings{chenpoint,
title={Point-MoE: Large-Scale Multi-Dataset Training with Mixture-of-Experts for 3D Semantic Segmentation},
author={Chen, Xuweiyi and Zhou, Wentao and RoyChowdhury, Aruni and Cheng, Zezhou},
booktitle={The Fourteenth International Conference on Learning Representations}
}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}